abcjsはABC記譜法で書いたテキストからブラウザ上で楽譜を表示できるJavascriptのライブラリ
Javascript library for inserting music in the browser. | abcjs Obsidianではobsidian-plugin-abcjsというプラグインがあり、ノート内で楽譜を表示することができる。

Appleのヘルスケアアプリのデータを使って、他のアプリでグラフを描こうと思ったが、エクスポートされるデータはXMLのため、そのままでは扱いにくい。
このため、XMLファイルから体重データを抜き出してCSVを出力するRubyスクリプトを書いた。
require 'nokogiri' require 'date' reader = Nokogiri::XML::Reader File.read('export.xml') data = [] reader.each do |node| if node.name == 'Record' && node.attributes['type'] == 'HKQuantityTypeIdentifierBodyMass' d = Date.parse(node.attributes['startDate']).strftime("%Y-%m-%d") data << [d, node.attributes['value']] end end data.sort.each {|d| puts d.join(',') } =begin <Record type="HKQuantityTypeIdentifierBodyMass" sourceName="1byone Health" sourceVersion="63" device="<<HKDevice: 0x3013e9b30>, name:iPhone, manufacturer:Apple, model:iPhone, hardware:iPhone, firmware:iPhone, software:17.5.1, localIdentifier:ja_JP, UDIDeviceIdentifier:ja_JP, creation date:2024-06-02 22:17:36 +0000>" unit="kg" creationDate="2024-06-17 07:17:17 +0900" startDate="2024-06-17 07:17:17 +0900" endDate="2024-06-17 07:17:17 +0900" value="71.9"/> =end 以下、ChatGPTにヘルスケアデータの構造を聞いた回答
Appleのヘルスケアアプリでエクスポートされるデータは、XML (Extensible Markup Language) フォーマットで提供されます。このフォーマットは、ヘルスデータを構造化して格納するための標準的な形式です。
データの構造と内容 # XMLヘッダー エクスポートされたファイルは、XMLヘッダーから始まります。
<?xml version="1.0" encoding="UTF-8"?> 全体のルート要素 データ全体は <HealthData> というルート要素でラップされています。
<HealthData locale="en_US"> ... </HealthData> データの各エントリー ヘルスケアのデータは、それぞれの記録を <Record> 要素として格納します。主な属性は以下の通りです:
type: データの種類(例: 歩数、心拍数など)。 sourceName: データのソース名(iPhone、Apple Watchなど)。 sourceVersion: ソースのバージョン情報。 unit: データの単位(例: count, bpm, kcal など)。 creationDate: データが作成された日時。 startDate: データの開始日時(測定期間の開始)。 endDate: データの終了日時(測定期間の終了)。 value: データの値(例: 歩数の数値、体重の値など)。 例:
crisp-game-libはブラウザゲームを開発するための軽量なゲームライブラリ。JavaScriptでゲームを開発し簡単に公開することができる
abagames/crisp-game-lib: Minimal JavaScript library for creating classic arcade-like mini-games running in the browser
ファイルの内容を昇順にソートして重複した行を1行にするTextwellのアクションを書いた。
いわゆる$ sort foobar | uniqするアクションです。
https://gist.github.com/htakeuchi/fd9e36227ad1688b31e9b84eafbf17a9
const { text, range } = T; const selectionStart = range.len > 0 ? range.loc : 0; const selectionEnd = range.len > 0 ? selectionStart + range.len : text.length; const lines = text.split('\n'); let pointerStart = 0; let replacingRangeLoc = 0; const hitLines = []; for (const line of lines) { const pointerEnd = pointerStart + line.length; if (pointerStart > selectionEnd) break; if ( (pointerStart <= selectionStart && selectionStart <= pointerEnd) || (pointerStart <= selectionEnd && selectionEnd <= pointerEnd) || (selectionStart < pointerStart && pointerEnd < selectionEnd) ) { if (hitLines.length === 0) replacingRangeLoc = pointerStart; hitLines.push(line); } pointerStart = pointerEnd + 1; // 1 means a line break. } const blankLines = []; const numLines = []; const strLines = []; hitLines.forEach((content) => { const intContent = parseInt(content); if (!content.match(/\S/)) { blankLines.push(content); // Ignore blank line } else if (isNaN(intContent)) { strLines.push(content); } else { numLines.push({ num: intContent, str: content }); } }); numLines.sort((a, b) => a.num - b.num); const sortedNumLines = numLines.map(({ str }) => str); strLines.sort((a, b) => a.toLowerCase().localeCompare(b.toLowerCase())); const sortedLines = [...blankLines, ...sortedNumLines, ...strLines]; // Remove duplicates const uniqueLines = [...new Set(sortedLines)]; // Join lines into text const replacingText = uniqueLines.join('\n'); T('replaceRange', { text: replacingText, replacingRange: { loc: replacingRangeLoc, len: selectionEnd - replacingRangeLoc }, selectingRange: { loc: replacingRangeLoc + replacingText.length, len: 0 }, });
このサイトはObsidianで管理しているノートをQuartzで公開しており、全てのテキストはMarkdownで書いている。
このため、Amazonの商品紹介をするのがなかなか面倒であり、これを改善するためのブックマークレットを書いた。
使い方 # Amazonの商品ページに行ってこのブックマークレットを起動すると、以下のようなMarkdownが生成され、クリップボードへコピーされる。
![[オン] ランニングシューズ Cloudmonster メンズ](https://a.media-amazon.com/images/I/51lG1xvL7nL._AC_SY200_.jpg) [[オン] ランニングシューズ Cloudmonster メンズ](https://www.amazon.co.jp/gp/product/B0CN337TNH/?tag=namaraiicom-22) 出力はこんな感じ。殺風景だけどMarkdownだけで書いていて、専用のCSSを当てていないのでやむをえない。
[オン] ランニングシューズ Cloudmonster メンズ
実装 # 実装はこんな感じ。Amazon(JP)で複数ジャンルの商品ページのHTMLを確認し、チェックした範囲では動作しているが、うまく動かないページもあると思う。
もし、動かないページをみつけたらこちらまでご連絡いただければ幸い。ブックマークレットへの変換は以下のページが便利です。
Bookmarklet スクリプト変換 (function() { function copyToClipboard(text) { navigator.clipboard.writeText(text).then(function() { alert('クリップボードにコピーされました'); }).catch(function(error) { console.error('クリップボードへのコピーに失敗しました', error); }); } function getElement(selector) { return document.querySelector(selector); } try { var size = 200; var asinElement = getElement('input#ASIN'); if (!asinElement) throw new Error('ASINが見つかりませんでした'); var asin = asinElement.value; var titleElement = getElement('span#productTitle'); if (!titleElement) throw new Error('製品名が見つかりませんでした'); var title = titleElement.textContent.trim(); var thumbnailUrl = getElement('img#landingImage')?.src || getElement('img[src*="_SY"]')?.src || getElement('input#productImageUrl')?.value || getElement('img[src*="_SX"]')?.src; if (!thumbnailUrl) { throw new Error('サムネイル画像が見つかりませんでした'); } var productUrl = 'https://www.amazon.co.jp/gp/product/' + asin + '/?tag=namaraiicom-22'; var modifiedUrl; var sizeMatch = thumbnailUrl.match(/_(_SY|_SX)(\d+)_/); if (sizeMatch && sizeMatch[2]) { modifiedUrl = thumbnailUrl.replace(/_(_SY|_SX)\d+_/, `_${sizeMatch[1]}${size}_`); } else if (thumbnailUrl.match(/_(SY|SX)(\d+)_/)) { modifiedUrl = thumbnailUrl.replace(/_(SY|SX)\d+_/, `_SY${size}_`); } else { modifiedUrl = thumbnailUrl; } var markdownContent = `\n\n[${title}](${productUrl})`; copyToClipboard(markdownContent); } catch (error) { console.error(error); } })();
bibinfo-exporter/script.js at main · goryugocast/bibinfo-exporterを参考にAmazonから書誌情報をへ取り込むブックマークレットを作成した。
直接Obsidianに取り込むのは自分の運用に合わないためTextwellへ追記するように。
こちらは書籍専用で、著者名や出版社、出版日などを取り込む。
Amazonの書誌情報をTextwellの追記するブックマークレット
javascript: (() => { const dest_path = 'notes'; //ファイルを格納するパス const amazon_id = 'namaraiicom-22'; // アフィリエイトID let p = document.getElementById("productTitle"); //書籍のタイトルの処理 p = p ? p : document.getElementById("ebooksProductTitle"); const title = p.innerText.trim(); let asin = document.getElementById('ASIN'); //ASIN番号の処理 const a = asin ? asin.value : document.getElementsByName('ASIN.0')[0].value; const url = `https://www.amazon.co.jp/exec/obidos/ASIN/${a}/${amazon_id}/`; const link = `[${title}](${url})`; let image = document.getElementById("imgTagWrapperId"); //書影の処理 image = image ? image : document.getElementById("ebooksImgBlkFront"); const imageurl = image.querySelector("img").getAttribute("src"); const c = document.getElementsByClassName('author'); const pub = []; const ct_list = []; // ctの各要素を保存する配列を新たに定義 for (let g = 0; g < c.length; g++) { const at = c[g].innerText.replace(/\r?\n/g, '').replace(/,/,''); const pu = at.match(/\(.+\)/); const ct = at.replace(/\(.+\)/,'').replace(/ /g,''); ct_list.push(ct); // ctを配列に追加 pub.push(`${pu} [[${ct}]]`); } const author = pub.join(' '); let h1title = `『${title}』`; h1title = h1title.replace(/[\\/:*?"<>|.]/g, char => ({ ':': ':', '\\': '\', '/': '/', '?': '?', '*': '*', '"': '”', '<': '<', '>': '>', '|': '|', '.': '.' }[char])); const mdimage = `[](${url})`; // 登録情報欄を取得 let detail = document.getElementById('detailBullets_feature_div'); if (!detail) { const subdoc = document.getElementById("product-description-iframe").contentWindow.document; detail = subdoc.getElementById("detailBullets_feature_div"); } const detailtext = detail.innerText; const pubdata = detailtext.split(/\n/); pubdata[2] = pubdata[2]?.slice(10); // 出版社 const date = new Date().toLocaleDateString('sv-SE'); const lines = `---%0D%0Atitle: "${h1title}"%0D%0Adate%3A%20${date}%0D%0Aupdated%3A%20${date}%0D%0Andl%3A%0D%0Atags%3A%20読書メモ%0D%0Adraft%3A%20true%0D%0A---%0D%0A${mdimage}%0D%0A-%20${link}%0D%0A-%20${author}%0d%0A-%20${pubdata[2]}%0D%0A%0D%0A%23%23 関連・思い出した本 %0d%0A%23%23 読書メモ%0d%0A`; const app = `textwell:///add?text=${lines}`; window.open(app); })(); こちらは一般的な商品の画像と商品名を取り込む。
Amazon商品の商品名と画像へのリンクをTextwellに追加するブックマークレット
javascript: (() => { const dest_path = "notes"; //ファイルを格納するパス const amazon_id = "namaraiicom-22"; // アフィリエイトID let p = document.getElementById("productTitle") || document.getElementById("ebooksProductTitle"); //書籍のタイトルの処理 const title = p.innerText.trim(); const asinElement = document.getElementById('ASIN') || document.getElementsByName('ASIN.0')[0]; //ASIN番号の処理 const a = asinElement.value; const url = `https://www.amazon.co.jp/exec/obidos/ASIN/${a}/${amazon_id}/`; const link = `[${title}](${url})`; const image = document.getElementById("landingImage"); const imageurl = image.getAttribute("src"); // 自分が必要なパラメータに変換 let h1title = title.replace(/[\\/:*?"<>|.]/g, char => ({ ':': ':', '\\': '\', '/': '/', '?': '?', '*': '*', '"': '”', '<': '<', '>': '>', '|': '|', '.': '.' }[char])); const mdimage = `[](${url})`; const lines = `${mdimage}%0D%0A%0D%0A${link}%0D%0A`; const app = `textwell:///add?text=${lines}`; window.open(app); })();
Hugoには他のCMSではよくある、機能を拡張するためのプラグインを提供する仕組みがない。
このため、あるテーマの中に便利なショートコードがあったとして、それを別のテーマで使用しようとした場合、
テーマディレクトリ/layouts/shortcodes配下のショートコードのソースを、別のテーマの/layouts/shortcodes配下、またはルート配下の/layouts/shortcodesへコピーする ショートコードにスタイルが設定されている場合、スタイルシートの中から必要な部分を抜き出し、別のテーマのスタイルシートへコピーする という煩雑な手順が必要となるが、先日、以下のショートコードのインストール手順を読んでいたら、うまい方法でショートコードを提供していた。
mfg92/hugo-shortcode-gallery: A theme components with a gallery shortcode for the static site generator hugo. まずショートコードのコードをテーマディレクトリ配下へcloneする。その後、config.tomlでテーマを以下のように指定する。
theme = ["your-main-theme", "hugo-shortcode-gallery"] そもそもテーマを複数指定できることを知らなかったが、この設定によりyour-main-themeテーマに加えhugo-shortcode-galleryテーマも参照されることになる。
そして、hugo-shortcode-gallery配下は以下のようなファイル構成になっている。
hugo-shortcode-gallery ├── LICENSE.md ├── README.md ├── assets │ └── shortcode-gallery │ ├── filterbar.sass │ └── font-awesome │ ├── compress-alt-solid.svg │ ├── expand-alt-solid.svg │ └── license.txt ├── config.toml ├── layouts │ └── shortcodes │ └── gallery.html └── static └── shortcode-gallery ├── jquery-3.7.0.min.js ├── justified_gallery │ ├── LICENSE │ ├── jquery.justifiedGallery.js │ ├── jquery.justifiedGallery.min.js │ ├── justifiedGallery.css │ └── justifiedGallery.min.css ├── lazy │ ├── jquery.lazy.js │ └── jquery.lazy.min.js └── swipebox ├── css │ ├── swipebox.css │ └── swipebox.min.css ├── img │ ├── icons.png │ ├── icons.svg │ └── loader.gif └── js ├── jquery.swipebox.js └── jquery.swipebox.min.js 14 directories, 23 files テーマと言ってもlayouts配下にあるのはショートコードのみである。そしてassetsとstaticディレクトリ配下にショートコードで使用するファイルだけを置くというのは、汎用的にショートコードを提供する方法として手軽で良いと思った。
さまざまなパターンの日本語文章をデータとして欲しいケースがあったので、指定したURLから本文らしき内容を抽出するスクリプトを書いた。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 require 'playwright' require 'readability' require 'html2text' # 指定したURLから本文らしき内容を抽出して返却する def html2text(url) Playwright.create(playwright_cli_executable_path: 'npx playwright') do |playwright| playwright.chromium.launch(headless: true) do |browser| begin page = browser.new_page page.goto(url, waitUntil: 'load') doc = Readability::Document.new(page.content) sleep 1 return {:title => page.title, :content => Html2Text.convert(doc.content) } rescue return {:title => nil, :content => nil } end end end end url = ARGV.shift doc = html2text(url) puts "#{doc[:title]}\n#{doc[:content]}" Javascriptでコンテンツを生成するページに対応するためPlaywrightを使用。
使用したライブラリ # cantino/ruby-readability: Port of arc90’s readability project to Ruby YusukeIwaki/playwright-ruby-client: Playwright client for Ruby soundasleep/html2text_ruby: A Ruby component to convert HTML into a plain text format.

C4モデルとは # ソフトウェアのアーキテクチャを表現するためのモデル。
コンテキスト(context) コンテナ(containers) コンポーネント(components) コード(code) で構成される。 C4モデルは特別な表記法を規定していない。以下、ダイアグラムの図はThe C4 model for visualising software architectureを参考に作成した。
flowchart TD ソフトウェアシステム:::system ソフトウェアシステム --> containerA(コンテナ) ソフトウェアシステム --> containerB(コンテナ) ソフトウェアシステム --> containerC(コンテナ) componentA1:::dot containerA:::dot --> componentA1(コンポーネント) componentA:::dot containerB --> componentA(コンポーネント) containerB --> componentB(コンポーネント) containerB --> componentC(コンポーネント) containerB:::container componentC:::dot componentA2:::dot containerC:::dot --> componentA2(コンポーネント) componentB --> codeA(コード) componentB --> codeB(コード) componentB --> codeC(コード) componentB:::component codeA:::code codeB:::code codeC:::code classDef dot fill:#eef,stroke:#f66,stroke-width:2px,color:#aaa,stroke-dasharray: 5 5 classDef system fill:#faa,stroke:#333,color:#fff,stroke-width:4px classDef container fill:#44f,stroke:#333,color:#fff,stroke-width:4px classDef component fill:#77f,stroke:#333,color:#fff,stroke-width:4px classDef code fill:#aaf,stroke:#333,color:#fff,stroke-width:4px レベル1 システムコンテキスト ダイアグラム # 対象システムが、それを使用する人や関連する他システムとの関係性、どのような位置づけにあるかを図示する。
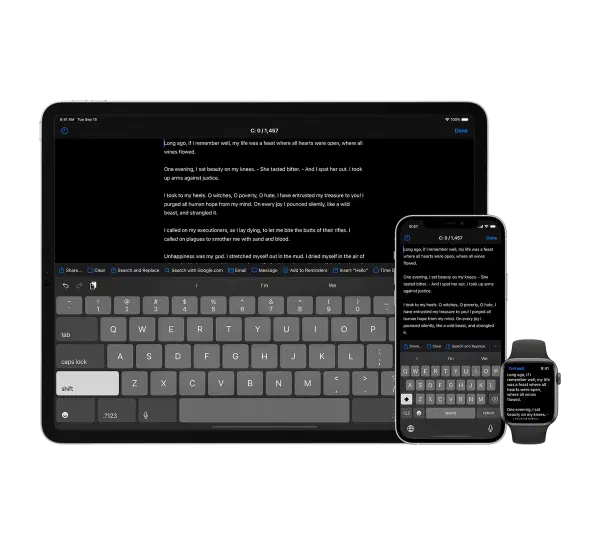
Textwell - The Modeless Textbox for iPhone, iPad, iPod touch, Mac, and Watch.
メモ、メッセージ、ブログ、検索、投稿など、あらゆる文章作成タスクに使用できる多目的テキストエディタ
ファイリングやスタイリングのための機能はないが、JavaScriptベースのカスタマイズ可能なアクション、自動履歴、クラウド同期などをサポートしており、シンプルで拡張性が高い
Mac版、iOS版、AppleWatch版がある
Textwell | URL Schemes
自作のアクションなど # ソートして重複行を削除するTextwellのアクション Obsidianのデイリーノートへ追記するTextwellのアクション Amazonから書誌情報をTextwellへ取り込むブックマークレット
ObsidianのデイリーノートへTextwell から追記するためのアクション。TextwellからObsidianのデイリーノートを書く方法 - Jazzと読書の日々を参考にさせていただき以下の修正を行った。
デイリーノートのディレクトリ構成(YYYY/MM/YYYY-MM-DD.mdとした) 新規作成ではなく追記に変更 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 // デイリーノートのルートディレクトリ Root = "journal"; url = "obsidian://"; d = new Date(); y = d.getFullYear(); m = Zero(d.getMonth()+1); // デイリーノートのディレクトリ構成対応(YYYY/MM/YYYY-MM-DD.md) Folder = Root + "/" + y + "/" + m; Title = y + "-" + m + "-" + Zero(d.getDate()); if(Folder) Title = Folder + "/" + Title; if(T.text) url+= "new?content=" + encodeURIComponent("\n") + T.stdin.text + "&file=" + encodeURIComponent(Title) + "&append"; T(url,{option:"cutWhole"}); function Zero(x){ return ("00"+x).slice(-2); }